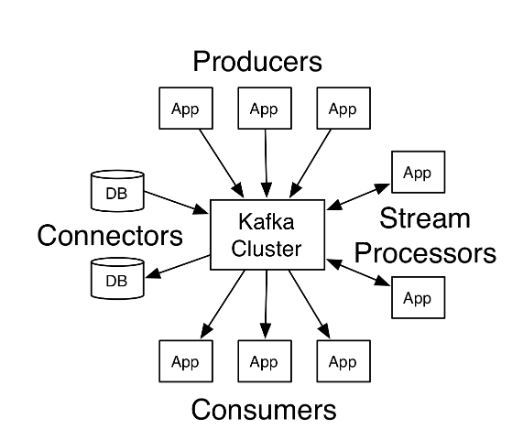
카프카는 메세지큐 서비스로 분산 환경에 특화 되있다고 한다. 보통 많이 알려진 RabbitMQ 와 동일한 메시지 큐지만 대용량 분석처리에 적합하다고 한다.
아직 ActiveMQ 밖에 사용해보지않았지만 개념으로 알아보도록하자
Kafka 특징
- 분산 처리를 이용한 메세징 처리를 한다.
클러스터링 구조를 지원하고 단일 시스템 보다 성능이나 장애에 뛰어나며 데이터 유일이 없다.
- 시스템 확장에 용이하다.
분산시스템을 기반으로 설계 되었기 떄문에 확장에 아주 용이하다. 서비스를 중단하지 않고 무중단으로 확장이 가능하다.
- 메세지를 메모리에 저장하지 않고 파일시스템에 저장한다.
RabbitMQ 같은 것들은 메모리에 보통 내용을 저장하고 있다가 메세지를 전송하고나면 메세지를 큐에서 삭제한다. 카프카는 데이터를 파일시스템에 저장한다. 그렇기 때문에 보관주기 안에는 메세지를 언제든지 읽어 가는게 가능하다. ( 기본 7일 )
- 배치 전송 처리
작은 메세지들은 묶어서 그룹핑 하여 처리 하여 네트워크상의 오버헤드를 줄임.
Kafka 용어

- Broker : 카프카가 설치된 서버 이다. 카프카 클러스터를 구성할경우 기본 1대 이상 서버들을 클러스터로 구성할수있다.
- Topic : 메세지들의 집합소이다. 프로듀서에서는 자신이 어느 토픽으로 메세지를 보낼지 정할수 있고 컨슈머는 어느 토픽에서 메세지를 가져올지 정할수 있다.

- Partition : 로드 밸런싱을 위해서 토픽 자체를 분할 한다. 파티션은 하나의 프로듀서가 메세지를 전송시 여러개로 분할하여 날릴수 있는 데 메세지를 4개를 순차적으로 보내서 4초가 걸린다고 가정했을때 파티션을 4개로 파티션을 하여 전송하면 보다 빠른속도로 전송이 가능하다. ( 단, 메세지의 순서는 보장되어야한다는 제약조건이 있음. 오프셋을 사용하여 파티션 내부의 메세지를 식별함. ) 빠른 전송을 위해선 파티션이 필요하며 파티션만 늘리는것이 아니라 그수만큼 프로듀서의 수로 맞추어 늘려줘야만 제대로된 성능 효과를 볼수 있다.
주의점은 파티션을 무한정으로 늘렸을 경우 자원낭비와 장애 발생시 복귀에 많은 자원이 소모 되므로 목표 처리량을 정해놓고 그에 맞게 설정을 해야한다. ( 최대 파티션수는 2000개 )
- Replication : 브로커간의 메세지를 복사한다. 브로커중 리더가 메세지를 저장하면 리더가 아닌 다른 팔로워들이 그 데이터를 복사해서 가지고있는다. 리더에 문제가 생겼을시 다른 팔로워가 리더로 선출 되어도 동일 데이터를 들고 있기때문에 서비스에 영향이 없게 운영이 가능하다.
ISR 을 이용하여 구성원과 리더를 구성하며 ISR 안에 속해 있어야만 리더선출 자격을 가진다.
- Produce : 메세지를 카프카로 송신하는 주체
- ack 설정 : 메세지 전달시 ack 설정에 따라 메세지 유실률과 처리량을 선택이 가능하다.
0 : ack 를 기다리지 않고 처리 , 유실률 ↑ 처리율 ↑
1 : 리더는 데이터를 기록은 하지만 , 모든 팔로워들의 상태는 확인 하지 않음 , 유실률 - , 처리율 -
-1 : 모든 ISR 을 확인 함. 유실율 ↓ 처리율 ↓
- 데이터를 보낼때 메세지 사이즈 크기와 메세지 보내기전 대기시간 , 대기 메모리량등을 프로듀서에서 설정이 가능하다.
- Consumer : 메세지를 수신하는 주체
- Apache Zookeeper : 분산 코디네이터 , 클러스트에 있는 서버들의 상태를 체크하고 분산시스템간의 정보 공유가 가능하도록 해주는 코디네이션 시스템 . 카프카 클러스터와 같으 사용시 기본적으로 주키퍼는 카프카 클러스터의 리더를 알고 있으며 시스템 구성시 카프카와 주키퍼는 다른 서버에서 구성하도록 한다. ( 주키퍼는 별도로 글을 작성 해야겠다 )
Kafka 사례
제일 유명한곳을 아래 두곳 같다. 국내에선 네이버나 카카오도 현재 사용중인것을 기술블로그 통해서 확인 했다. 실제 카프카 관련 서적 저자가 카카오에 계신 분인것도 확인했다. 국내에선 충분히 사용 가능할것 같고 활용도는 정말 아주 높을 것으로 보인다.
안정성이나 성능보장성은 넷플릭스에서 서비스에 운영중이니 성능이나 안정성은 검증이 되지 않았나 싶다.
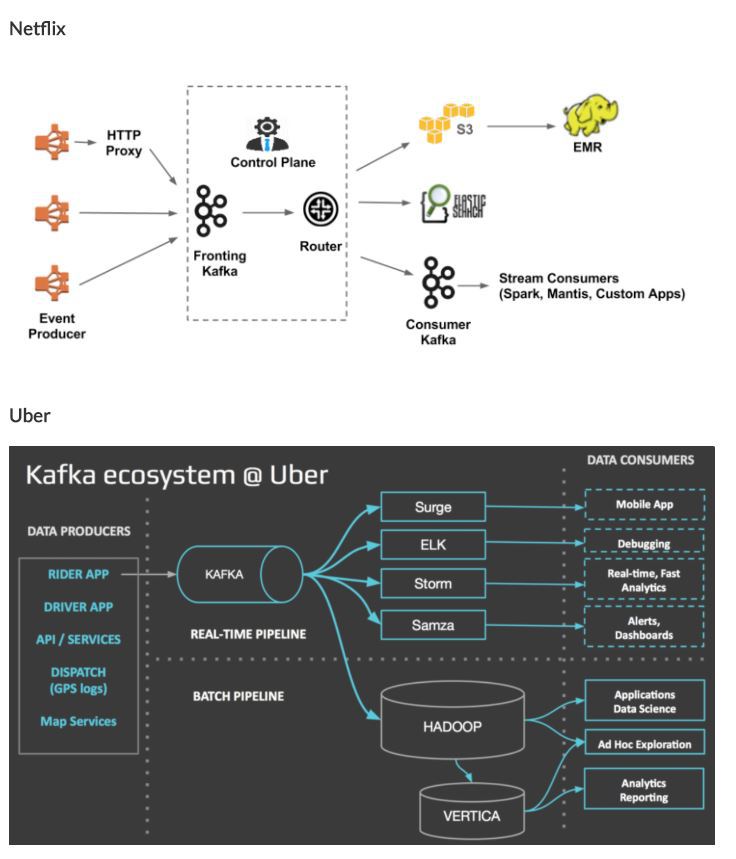
이제 카프카를 시작한다. 카프카 단독으로도 충분히 좋은 플랫폼이라 생각하지만 적용 사례들만을 봐도 단순 카프카만으로 서비스를 하진 않는다. Spark , strom , Samza , hadoop 등 충분히 다른 플랫폼기술들과 연동이 가능하다고 본다. 단순 로그성 데이터를 수집하는것 이외에 실시간 데이터 추천이라든가 빅데이터를 수집하는 경우에도 충분히 활용하는게 가능할것 같다.
'JAVA' 카테고리의 다른 글
| restful API 규칙 (0) | 2021.03.03 |
|---|---|
| java 리스트간 비교, 값 체크 (0) | 2021.02.24 |
| RestTemplate VS WebClient (0) | 2021.02.24 |
| 비동기, 동기, 블로킹, 논블로킹 (0) | 2021.02.19 |
| JAVA11 (0) | 2019.10.04 |