반응형
R2dbc
jasync-sql
'JAVA' 카테고리의 다른 글
| CentOS File 인코딩 (0) | 2021.11.30 |
|---|---|
| JAVA CS핵심 내용 (0) | 2021.03.10 |
| restful API 규칙 (0) | 2021.03.03 |
| java 리스트간 비교, 값 체크 (0) | 2021.02.24 |
| Kafka (0) | 2021.02.24 |
R2dbc
jasync-sql
| CentOS File 인코딩 (0) | 2021.11.30 |
|---|---|
| JAVA CS핵심 내용 (0) | 2021.03.10 |
| restful API 규칙 (0) | 2021.03.03 |
| java 리스트간 비교, 값 체크 (0) | 2021.02.24 |
| Kafka (0) | 2021.02.24 |
iconv -f euc-kr -t utf-8 test.txt > test_result.txt
| WebFlux 비동기 Reactive JDBC (0) | 2022.07.05 |
|---|---|
| JAVA CS핵심 내용 (0) | 2021.03.10 |
| restful API 규칙 (0) | 2021.03.03 |
| java 리스트간 비교, 값 체크 (0) | 2021.02.24 |
| Kafka (0) | 2021.02.24 |
빌드를 하다보면 Gradle 로 빌드를 하게되어 개발 테스트시 속도가 저하될수있다.

File | Settings | Build, Execution, Deployment | Build Tools | Gradle 들어가서
Build and run using 을 IntelliJ 로 변경시 IntelliJ 로 빌드를 진행 할수있다.

| JAVA private static final, private final 차이 (0) | 2021.06.01 |
|---|---|
| Intellij 라인 번호, 공백 표시 (0) | 2021.05.17 |
| Spring Cloud Netflix (0) | 2020.03.18 |
| OAuth2 (0) | 2020.03.18 |
| 정규식 표현(Regular Expression)이란? (0) | 2019.11.29 |
private static final Integer THREAD_COUNT = 10;
private final Integer THREAD_COUNT = 10;
- private static final을 선언한 변수를 사용하면 재할당하지 못하며, 메모리에 한 번 올라가면 같은 값을 클래스 내부의 전체 필드, 메서드에서 공유한다.
- private final을 선언한 변수를 사용하면 재할당하지 못하며, 해당 필드, 메서드별로 호출할 때마다 새로이 값이 할당(인스턴스화)한다.
그렇다면 상수로 사용하려고 할 때, 그 값은 변하지않는 값을 호출할 때마다 새롭게 인스턴스화 하여 올릴필요가 없다.
private static final 로 상수가 선언된 부분을 메모리에서 가져다 쓰면된다.
| IntelliJ Gradle Run 변경 (0) | 2021.06.08 |
|---|---|
| Intellij 라인 번호, 공백 표시 (0) | 2021.05.17 |
| Spring Cloud Netflix (0) | 2020.03.18 |
| OAuth2 (0) | 2020.03.18 |
| 정규식 표현(Regular Expression)이란? (0) | 2019.11.29 |

1. 라인번호
File | Settings | Editor | General | Appearance
- Show line numbers 체크
2. 공백 표기
File | Settings | Editor | General | Appearance
- Show whitespaces 체크
| IntelliJ Gradle Run 변경 (0) | 2021.06.08 |
|---|---|
| JAVA private static final, private final 차이 (0) | 2021.06.01 |
| Spring Cloud Netflix (0) | 2020.03.18 |
| OAuth2 (0) | 2020.03.18 |
| 정규식 표현(Regular Expression)이란? (0) | 2019.11.29 |
public interface CalculatorInterface {
int add(int x, int y);
int sub(int x, int y);
default int mul(int x, int y) {
return x * y;
}
static String value(int i) {
return String.valueOf(i);
}
}
public class Calculator implements CalculatorInterface {
@Override
public int add(int x, int y) {
return x + y;
}
@Override
public int sub(int x, int y) {
return x - y;
}
}
public class CalculatorTest {
@Test
public void 인터페이스_mul_확인() {
Calculator calculator = new Calculator();
Assert.assertEquals(calculator.mul(2, 5), 10);
}
@Test
public void 인터페이스_static_value_확인() {
Assert.assertEquals(CalculatorInterface.value(10), "10");
}
}
자바는 메모리 관리를 개발자가 아닌 GC(Garbage Collector)라는 쓰레드를 생성하여 사용하지 않는 객체들을 제거한다.
일반적으로 자바에서는 JVM에 의해 자동으로 Garbage Collection이 실행된다. 더 이상 사용되지 않은 객체들을 점검하여 제거한다.
GC(Garbage Collection)
Spring Boot는 개발의 simpify를 최우선으로 한 java framework입니다.
Spring Boot는 Spring MVC 기반의 Java Web 개발을 더 쉽게 만들어주는 특징은 다음과 같습니다.
둘 다, 스프링 프레임워크의 범주에 포함됩니다. 각각 다른 문제를 해결하기 위한 프레임워크입니다.
Spring MVC는 Model-View-Controller 디자인패턴을 사용하는 일관된 구조를 제공함으로써 자바 웹 개발을 쉽게 하게 해줍니다. 반면, 스프링부트는 Spring MVC를 포함하는 Spring framework를 가지고 웹 개발을 하면서 가지는 고통스러운 설정, 의존성 관리 그리고 애플리케이션 실행을 더 간편하고 쉽게 개발하게 해줍니다.
- starter를 통한 자동 권장 버전 관리, 편리한 의존성 관리
- 내장서버가 있기때문에 jar 파일로 간단하게 배포 가능
IOC - 객체의 생성 생명주기의 관리까지 모든 객체에 대한 제어권이 바뀌었다는 것을 말합니다.
객체를 생성 및 제거하는 것은 비용이 많이 들기 때문에 스프링 컨테이너에서 IOC를 구현해주어 자주 사용하는 객체를 제어함
DI - 의존성 주입으로 의존적인 객체를 직접 생성하거나 제어하는것이 아니라 외부에서 결정해서 연결시키는것
@Componet 어노테이션으로 의존객체로 만들고
AOP - 공통기능을 모든 모듈에 적용하기 위한 방법
- 관점지향프로그래밍 메소드 전 후 지점에 설정 가능하며 트랜잭션, 에러처리와 같은 기능에 적합함
(로깅', '트랜잭션', '에러 처리')
@Transactional, interceptor, filter aop의 일종
@Before: 대상 메서드의 수행 전
@After: 대상 메서드의 수행 후
@After-returning: 대상 메서드의 정상적인 수행 후
@After-throwing: 예외발생 후
@Around: 대상 메서드의 수행 전/후
Filter - 서블릿 필터는 DispatcherServlet 이전에 실행이 되는데 필터가 동작하도록 지정된 자원의 앞단에서 요청내용을 변경하거나, 여러가지 체크를 수행할 수 있다.
init() - 필터 인스턴스 초기화
ㆍdoFilter() - 전/후 처리
ㆍdestroy() - 필터 인스턴스 종료
Interceptor - 컨트롤러를 호출하기 전 후단계에 대한 요청 응답에 대해 처리함
(로그인체크, 권한체크)
preHandler() - 컨트롤러 메서드가 실행되기 전
postHanler() - 컨트롤러 메서드 실행직 후 view페이지 렌더링 되기 전
afterCompletion() - view페이지가 렌더링 되고 난 후
디스패처 핸들링 위치차이 필터는 dispatcher를 거치지 않고 인터셉터는 dispatcher를 거침
그렇기 때문에 filter에서는 pathvariable을
잡을 수가 없음
필터는 주로 인증관련에서 사용 인터셉터는 요청값 확인에 사용함
싱글턴패턴 - 객체를 하나만 생성해서 생성된 객체를 어디에서든지 참조할수 있도록 하는 패턴
(고정된 메모리 영역을 얻으면서 한번의 new로 인스턴스를 사용하기 떄문에 메모리 낭비를 방지할수있음)
private로 외부에서 접근못하도록하고 instance 함수를 만들어 그 안에 new로 객체생성
전략패턴 - 객체가 할 수 있는 행위들 각각을 전략으로 만들어 놓고 수정이 필요한 경우 전략을 바꾸는 것만으로 행위의 수정이 가능하도록 만든 패턴입니다.
팩토리 메소드 패턴 - 객체를 생성하기 위한 인터페이스를 정의하는데, 어떤 클래스의 인스턴스를 만들지는 서브클래스에서 결정하게 만든다.
템플릿 메서드 패턴 - 서브 클래스로 캡슐화해 구조는 바꾸지 않고 상황에 맞게 서브클래스를 이용해 수행 내역을 변경해주는 패턴
커멘트패턴 - 실행될 기능을 캡슐화 함으로써 주어진 여러 기능을 실행할 수 있는 재사용성이 높은 클래스 설계하는 패턴
빌더패턴 - 여러개의 파라미터를 전달할때도 어떤한값이 어떤한 의미인지 파악할수 있어서 사용, 유지보수에 용이함
어댑터와 프록시 패턴(두 클랙스간에 하나의 클래스를 두는 구조)
차이점- 어댑터는 하나의 인터페이스에 맞추는게 목적이고
프록시는 다양한 방식으로 로직 컨트롤이 목적
타임리프 장점
- 템플릿 코드 자체가 html이기 때문에 뷰파일을 was없이도 브라우저에서 직접 띄워볼수가있음
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(
excludeFilters = {@Filter(
type = FilterType.CUSTOM,
classes = {TypeExcludeFilter.class}
), @Filter(
type = FilterType.CUSTOM,
classes = {AutoConfigurationExcludeFilter.class}
)}
)
대표적으로 @SpringBootConfiguration, @EnableAutoConfiguration ,@ComponentScan 3가지가있다.
configuration : 개발자가 직접 제어가 불가능한 외부 라이브러리 또는 설정을 위한 클래스를 Bean으로 등록할 때 @Bean 어노테이션을 활용
component : 개발자가 직접 개발한 클래스를 Bean으로 등록하고자 하는 경우 @Component 어노테이션을 활용
객체 생성 - 초기화 - 사용 - 소멸 순으로 유지된다.
GC
- heap영역의 오브젝트 중 stack에서 도달 불가능한 오브젝트들은 가비지 컬렉션의 대상이됨
Spring Boot auto-configuration가 classpath를 체크합니다. 체크해서 예를 들어 thymeleaf가 있으면, Thymelead template resolver, view resolver, and a template engine 이 것들을 자동으로 설정해 줍니다.
만약, Spring Data JPA가 classpath에 있으면, 자동으로 repository interface들로부터 repository implementations를 만들어줍니다.
starter dependency는 스프링부트에서 의존성 관리 문제를 해결해주는 역할을 합니다. 우리가 스프링부트를 사용할 때, JPA나 Thymeleaf Template가 현재 프로젝트에 적합한 버전이 무엇인지 알아야하거나 필요한 의존성 리스트를 상세하게 알 필요가 없습니다. 단지 Gradle이나 Maven build file에 추가해주면됩니다.
starter가 Maven이나 Gradle file에 등록한 의존성jar를 자동으로 프로젝트에 로드해 줍니다.
spring-boot-starter-web를 의존성 추가하면, Spring MVC Jar를 프로젝트에 import합니다.
application.properties파일에 정의하면 되고, springboot가 자동으로 읽습니다. 예로 server.port=9000으로 하면, 내장 톰켓이 실행되면, 디폴트 8080이 아니라 9000으로 앱이 실행됩니다.
YAML(야믈, 와이엠엘(.yml))은 JSON의 상위집합(superset)으로, 계층적 뼈대 구조를 설정하는데 편리한 형식(format)입니다. SpringApplication은 classpath에 있는 SnakeYAML library를 가지고 있을 때, 속성(properties)의 대안으로 자동적으로 YAML을 지원합니다.
spring-boot-starter는 가장 기본적인 라이브러리고, 이것이 있으면 SnakeYAML 은 자동으로 제공됩니다.
JDK 8에서 추가된 Stream API
컬렉션, 배열등의 저장 요소를 하나씩 참조하며 함수형 인터페이스(람다식)를 적용하며 반복적으로 처리할 수 있도록 해주는 기능
POJO는 말 그대로 해석을 하면 오래된 방식의 간단한 자바 오브젝트
쉽게 생각해서 순수한 자바 오브젝트라고 생각하면된다
예) getter, setter 가 메소드로 이루어진 Value Object 라고 생각하면된다.
비동기란 말 그대로 동시에 일어나지 않는다는 의미한다.
즉, 요청과 결과가 동시에 일어나지 않아 바로 결과가 주어지지 않고 나중에 처리된다
동기란 비동기와 반대로 동시에 일어난다는 말한다. 따라서 요청과 그 결과가 동시에 일어나서
요청을 하면 바로 그 요청한 자리에서 결과가 주어지며
시간이 얼마가 걸리든 상관 안하고 요청한 그 자리에서 결과를 주겠다는 약속같은 것이다.
즉, 요청과 결과가 한자리에서 동시에 일어난다
* 이렇게 동기와 비동기를 구분하는 이유는
동기와 비동기를 굳이 구분하는 이유는 상황에 따라서 장단점이 있기 때문인데
동기방식은 매우 설계가 간단하고 직관적이지만, 결과가 주어질 때까지 아무것도 못하고 대기해야 하는 단점이있고
비동기방식은 좀더 복잡하지만 결과가 주어지는 시간이 길어져도 그 시간 동안 다른 작업을 할 수 있으므로 좀더 효율적으로 자원을 사용할 수 있는 장점이있다
블로킹은 말 그대로 작업이 중단된다는 의미. 네트워크 통신에서 요청이 발생하고 완료될 때까지 모든 일을 중단한 상태로 대기해야 하는 것을 블로킹 방식이라 한다.
논블러킹은 말 그대로 중단되지 않는다는 말. 통신이 완료 될 때까지 중단되는 블로킹의 반대 개념이다.
논블로킹 방식은 아무래도 통신이 완료될 때까지 기다리지 않고 다른 작업을 수행할 수 있으므로 경우에 따라 효율이나 반응속도가 더 뛰어나다.

REST 란 “Representational State Transfer” 의 약자이다. 월드 와이드 웹과 같은 분산 하이퍼미디어 시스템을 위한 소프트웨어 아키텍처의 한 형식이다.
REST란, “웹에 존재하는 모든 자원(이미지, 동영상, DB 자원)에 고유한 URI를 부여해 활용”하는 것으로, 자원을 정의하고 자원에 대한 주소를 지정하는 방법론을 의미한다고 한다.
이런 REST의 형식을 따른 시스템을 RESTful 이라고 부른다.
HTTP URI 를 통해 자원을 명시하고 HTTP Method를 통해 해당 자원의 대한 CRUD Operation을 적용한다.
적은 양의 스레드와 최소한의 하드웨어 자원으로 동시성을 핸들링하기 위해 만들어졌다. 서블릿 3.1이 논블로킹을 지원하지만, 일부분이다. 이는 새로운 공통 API가 생긴 이유가 됐으며, netty와 같은 잘 만들어진 async, non-blocking 서버를 사용한다.
비동기 논블로킹 환경에서 자리를 잡은 서버(e.g. Netty) spring 버전이라고 생각하면된다.
Mono는 0-1개의 결과만을 처리하기 위한 Reactor의 객체이고, Flux는 0-N개인 여러 개의 결과를 처리하는 객체입니다.
NodeJS와 같은 비동기 소켓서버 프레임워크
Vert.x는 nodejs와 마찬가지로 single thread model이며

데이터 흐름과 전달에 관한 프로그래밍 패러다임
데이터 흐름을 먼저 정의하고 데이터가 변경되었을 때 연관되는 함수나 수식이 업데이트되는 방식
사용자 입장에서 보자면 Reactive Programming이란 실시간으로 반응을 하는 프로그래밍을 말합니다. 예를 들면, 네이버 검색창에 단어를 하나씩 입력할 때마다 관련 검색어들이 자동완성으로 바로바로 제시되는 것이나, 페이스북 포스트에 '좋아요' 버튼을 누르면 해당 포스트를 보고 있는 다른 유저의 '좋아요' 카운트가 페이지 새로 고침이 없어도 실시간으로 올라가는 것을 말합니다.
프레임워크는 전체적인 흐름을 자체적으로 가지고 있어 프로그래머는 그 안에서 필요한 코드를 작성합니다. 반면에 라이브러리는 프로그래머가 전체적인 흐름을 가지고 있어 라이브러리를 자신이 원하는 기능을 구현하고 싶을 때 가져다 사용할 수 있다
1. 커넥션 유지
- 1.0은 요청마다 TCP 세션을 맺어야 한다.
(1 GET / 1Connection)
- 1.1 은 Persistent 기능을 이용하여 TCP 세션을통해 여러개의 컨텐츠 요청이 가능하다.
(N GET / 1Connection)
2. 호스트 헤더
- 버추얼 호스팅을 지원한다
(여러개의 도메인으로 하나의 서버에 접근가능)
3. 강력한 인증 절차
프록시가 사용자인증을 요구하는헤더가 생성되었다.
| WebFlux 비동기 Reactive JDBC (0) | 2022.07.05 |
|---|---|
| CentOS File 인코딩 (0) | 2021.11.30 |
| restful API 규칙 (0) | 2021.03.03 |
| java 리스트간 비교, 값 체크 (0) | 2021.02.24 |
| Kafka (0) | 2021.02.24 |
안녕하세요. 오늘은 restful api의 규칙을 알아봅시다.

REST 란 “Representational State Transfer” 의 약자이다. 월드 와이드 웹과 같은 분산 하이퍼미디어 시스템을 위한 소프트웨어 아키텍처의 한 형식이다.
REST란, “웹에 존재하는 모든 자원(이미지, 동영상, DB 자원)에 고유한 URI를 부여해 활용”하는 것으로, 자원을 정의하고 자원에 대한 주소를 지정하는 방법론을 의미한다고 한다.
이런 REST의 형식을 따른 시스템을 RESTful 이라고 부른다.
HTTP URI 를 통해 자원을 명시하고 HTTP Method를 통해 해당 자원의 대한 CRUD Operation을 적용한다.
REST API 설계시 가장 중요한 항목은 아래 두가지이다.
1. URI는 정보의 자원을 표현해야 한다는 점
2. 자원에 대한 행위는 HTTP Method(GET, POST, PUT, DELETE)로 표현한다는 점
1. 소문자를 사용한다.
주소에서 대소문자를 구분하므로, 카멜방식이 아닌 소문자를 사용하여 작성한다.
//안좋은 예
https://localhost:8080/ddoriya/user/getUsers
//좋은 예
https://localhost:8080/ddoriya/user/get-users
2. 가급적 하이픈 사용은 최소화하지만 정확한 표현을 위해 - 을 사용하여 사용구분을 만든다.
가급적 하이픈의 사용도 최소화하며, 정확한 의미나 표현을 위해 단어의 결합이 불가피한 경우에 사용한다.
//안좋은 예
https://localhost:8080/ddoriya/user/getUsers
//좋은 예
https://localhost:8080/ddoriya/user/get-users
3.파일 확장자는 URI에 포함시키지 않는다.
REST API에서는 메시지 바디 내용의 포맷을 나타내기 위한 파일 확장자를 URI 안에 포함시키지 않습니다. Accept header를 사용하도록 한다.
//안좋은 예
GET https://localhost:8080/ddoriya/user/photo.jpg
GET https://localhost:8080/ddoriya/user/photo
HTTP/1.1 Host: restapi.example.com Accept: image/jpg
4. 가급적 전달하고자하는 자원의 명사를 사용하되, 컨트롤 자원을 의미하는 경우 예외적으로 동사를 허용한다.
//안좋은 예
https://localhost:8080/ddoriya/posts/duplicating
//좋은 예
https://localhost:8080/ddoriya/posts/duplicate
| CentOS File 인코딩 (0) | 2021.11.30 |
|---|---|
| JAVA CS핵심 내용 (0) | 2021.03.10 |
| java 리스트간 비교, 값 체크 (0) | 2021.02.24 |
| Kafka (0) | 2021.02.24 |
| RestTemplate VS WebClient (0) | 2021.02.24 |
리스트간 비교 anyMatch, noneMatch
문자열 비교에 따른 true, false 리턴
@Test
public void 리스트비교(){
List<String> allList = new ArrayList<>();
allList.add("1");
allList.add("2");
allList.add("3");
List<String> comparisonList = new ArrayList<>();
comparisonList.add("2");
List<String> anyMatchList = allList.stream()
.filter(target -> comparisonList.stream().anyMatch(Predicate.isEqual(target)))
.collect(Collectors.toList());
List<String> noneMatchList = allList.stream()
.filter(target -> comparisonList.stream().noneMatch(Predicate.isEqual(target)))
.collect(Collectors.toList());
System.out.println(anyMatchList); // 2
System.out.println(noneMatchList); // 1, 3
//리스트에 값이 있는지 체크
//1. for문으로 하였을 경우
boolean isResult = false;
for(String comparison : comparisonList){
if(comparison.equals("2")){
isResult = true;
break;
}
}
//2. stream 사용
if (comparisonList.stream().anyMatch(w -> w.equals("2"))) {
System.out.println("해당값이 있습니다.");
}
}
| JAVA CS핵심 내용 (0) | 2021.03.10 |
|---|---|
| restful API 규칙 (0) | 2021.03.03 |
| Kafka (0) | 2021.02.24 |
| RestTemplate VS WebClient (0) | 2021.02.24 |
| 비동기, 동기, 블로킹, 논블로킹 (0) | 2021.02.19 |
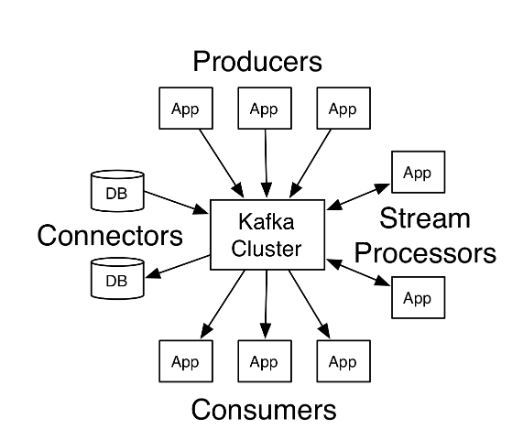
카프카는 메세지큐 서비스로 분산 환경에 특화 되있다고 한다. 보통 많이 알려진 RabbitMQ 와 동일한 메시지 큐지만 대용량 분석처리에 적합하다고 한다.
아직 ActiveMQ 밖에 사용해보지않았지만 개념으로 알아보도록하자
Kafka 특징
- 분산 처리를 이용한 메세징 처리를 한다.
클러스터링 구조를 지원하고 단일 시스템 보다 성능이나 장애에 뛰어나며 데이터 유일이 없다.
- 시스템 확장에 용이하다.
분산시스템을 기반으로 설계 되었기 떄문에 확장에 아주 용이하다. 서비스를 중단하지 않고 무중단으로 확장이 가능하다.
- 메세지를 메모리에 저장하지 않고 파일시스템에 저장한다.
RabbitMQ 같은 것들은 메모리에 보통 내용을 저장하고 있다가 메세지를 전송하고나면 메세지를 큐에서 삭제한다. 카프카는 데이터를 파일시스템에 저장한다. 그렇기 때문에 보관주기 안에는 메세지를 언제든지 읽어 가는게 가능하다. ( 기본 7일 )
- 배치 전송 처리
작은 메세지들은 묶어서 그룹핑 하여 처리 하여 네트워크상의 오버헤드를 줄임.
Kafka 용어

- Broker : 카프카가 설치된 서버 이다. 카프카 클러스터를 구성할경우 기본 1대 이상 서버들을 클러스터로 구성할수있다.
- Topic : 메세지들의 집합소이다. 프로듀서에서는 자신이 어느 토픽으로 메세지를 보낼지 정할수 있고 컨슈머는 어느 토픽에서 메세지를 가져올지 정할수 있다.

- Partition : 로드 밸런싱을 위해서 토픽 자체를 분할 한다. 파티션은 하나의 프로듀서가 메세지를 전송시 여러개로 분할하여 날릴수 있는 데 메세지를 4개를 순차적으로 보내서 4초가 걸린다고 가정했을때 파티션을 4개로 파티션을 하여 전송하면 보다 빠른속도로 전송이 가능하다. ( 단, 메세지의 순서는 보장되어야한다는 제약조건이 있음. 오프셋을 사용하여 파티션 내부의 메세지를 식별함. ) 빠른 전송을 위해선 파티션이 필요하며 파티션만 늘리는것이 아니라 그수만큼 프로듀서의 수로 맞추어 늘려줘야만 제대로된 성능 효과를 볼수 있다.
주의점은 파티션을 무한정으로 늘렸을 경우 자원낭비와 장애 발생시 복귀에 많은 자원이 소모 되므로 목표 처리량을 정해놓고 그에 맞게 설정을 해야한다. ( 최대 파티션수는 2000개 )
- Replication : 브로커간의 메세지를 복사한다. 브로커중 리더가 메세지를 저장하면 리더가 아닌 다른 팔로워들이 그 데이터를 복사해서 가지고있는다. 리더에 문제가 생겼을시 다른 팔로워가 리더로 선출 되어도 동일 데이터를 들고 있기때문에 서비스에 영향이 없게 운영이 가능하다.
ISR 을 이용하여 구성원과 리더를 구성하며 ISR 안에 속해 있어야만 리더선출 자격을 가진다.
- Produce : 메세지를 카프카로 송신하는 주체
- ack 설정 : 메세지 전달시 ack 설정에 따라 메세지 유실률과 처리량을 선택이 가능하다.
0 : ack 를 기다리지 않고 처리 , 유실률 ↑ 처리율 ↑
1 : 리더는 데이터를 기록은 하지만 , 모든 팔로워들의 상태는 확인 하지 않음 , 유실률 - , 처리율 -
-1 : 모든 ISR 을 확인 함. 유실율 ↓ 처리율 ↓
- 데이터를 보낼때 메세지 사이즈 크기와 메세지 보내기전 대기시간 , 대기 메모리량등을 프로듀서에서 설정이 가능하다.
- Consumer : 메세지를 수신하는 주체
- Apache Zookeeper : 분산 코디네이터 , 클러스트에 있는 서버들의 상태를 체크하고 분산시스템간의 정보 공유가 가능하도록 해주는 코디네이션 시스템 . 카프카 클러스터와 같으 사용시 기본적으로 주키퍼는 카프카 클러스터의 리더를 알고 있으며 시스템 구성시 카프카와 주키퍼는 다른 서버에서 구성하도록 한다. ( 주키퍼는 별도로 글을 작성 해야겠다 )
Kafka 사례
제일 유명한곳을 아래 두곳 같다. 국내에선 네이버나 카카오도 현재 사용중인것을 기술블로그 통해서 확인 했다. 실제 카프카 관련 서적 저자가 카카오에 계신 분인것도 확인했다. 국내에선 충분히 사용 가능할것 같고 활용도는 정말 아주 높을 것으로 보인다.
안정성이나 성능보장성은 넷플릭스에서 서비스에 운영중이니 성능이나 안정성은 검증이 되지 않았나 싶다.
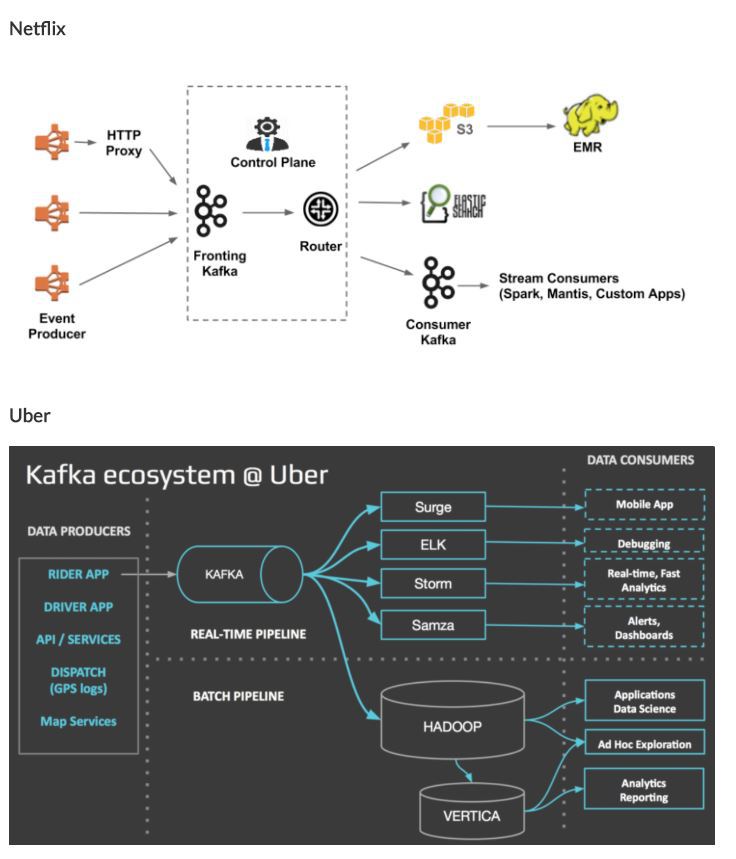
이제 카프카를 시작한다. 카프카 단독으로도 충분히 좋은 플랫폼이라 생각하지만 적용 사례들만을 봐도 단순 카프카만으로 서비스를 하진 않는다. Spark , strom , Samza , hadoop 등 충분히 다른 플랫폼기술들과 연동이 가능하다고 본다. 단순 로그성 데이터를 수집하는것 이외에 실시간 데이터 추천이라든가 빅데이터를 수집하는 경우에도 충분히 활용하는게 가능할것 같다.
| restful API 규칙 (0) | 2021.03.03 |
|---|---|
| java 리스트간 비교, 값 체크 (0) | 2021.02.24 |
| RestTemplate VS WebClient (0) | 2021.02.24 |
| 비동기, 동기, 블로킹, 논블로킹 (0) | 2021.02.19 |
| JAVA11 (0) | 2019.10.04 |
Spring 어플리케이션에서 HTTP 요청을 할 땐 주로 RestTemplate 을 사용했었습니다. 하지만 Spring 5.0 버전부터는 RestTemplate 은 유지 모드로 변경되고 향후 deprecated 될 예정입니다.
RestTemplate 의 대안으로 Spring 에서는 WebClient 사용을 강력히 권고하고 있으며 다음과 같은 특징을 가지고 있습니다.
Reactive 환경과 MSA를 생각하고 있다면 WebClient 사용을 적극 권장해 드리며, 기본 설정부터 Method 별 사용법까지 차근차근 알아보도록 하겠습니다.
spring 3.0 부터 지원한다. 스프링에서 제공하는 http 통신에 유용하게 쓸 수 있는 템플릿이며, HTTP 서버와의 통신을 단순화하고 RESTful 원칙을 지킨다. jdbcTemplate 처럼 RestTemplate 도 기계적이고 반복적인 코드들을 깔끔하게 정리해준다. 요청보내고 요청받는데 몇줄 안될 정도..
org.springframework.http.client 패키지에 있다. HttpClient는 HTTP를 사용하여 통신하는 범용 라이브러리이고, RestTemplate은 HttpClient 를 추상화(HttpEntity의 json, xml 등)해서 제공해준다. 따라서 내부 통신(HTTP 커넥션)에 있어서는 Apache HttpComponents 를 사용한다. 만약 RestTemplate 가 없었다면, 직접 json, xml 라이브러리를 사용해서 변환해야 했을 것이다.

예제
import org.apache.http.client.HttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.springframework.http.client.HttpComponentsClientHttpRequestFactory;
import org.springframework.web.client.RestTemplate;
public class RestTemplateTest {
public static void main(String[] args) {
HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory();
factory.setReadTimeout(5000); // 읽기시간초과, ms
factory.setConnectTimeout(3000); // 연결시간초과, ms
HttpClient httpClient = HttpClientBuilder.create().setMaxConnTotal(100) // connection pool 적용
.setMaxConnPerRoute(5) // connection pool 적용
.build();
factory.setHttpClient(httpClient); // 동기실행에 사용될 HttpClient 세팅
RestTemplate restTemplate = new RestTemplate(factory);
String url = "http://testapi.com/search?text=1234";
Object obj = restTemplate.getForObject("요청할 URI 주소", "응답내용과 자동으로 매핑시킬 java object");
System.out.println(obj);
}
}
WebClient는 Spring5 에 추가된 인터페이스다. spring5 이전에는 비동기 클라이언트로 AsyncRestTemplate를 사용을 했지만 spring5 부터는 Deprecated 되어 있다. 만약 spring5 이후 버전을 사용한다면 AsyncRestTemplate 보다는 WebClient 사용하는 것을 추천한다. 아직 spring 5.2(현재기준) 에서 AsyncRestTemplate 도 존재하긴 한다.
기본적으로 사용방법은 아주 간단하다. WebClient 인터페이스의 static 메서드인 create()를 사용해서 WebClient 를 생성하면 된다. 한번 살펴보자.
@Test
void test1() {
WebClient webClient = WebClient.create("http://localhost:8080");
Mono<String> hello = webClient.get()
.uri("/sample?name={name}", "wonwoo")
.retrieve()
.bodyToMono(String.class);
StepVerifier.create(hello)
.expectNext("hello wonwoo!")
.verifyComplete();
}
@Test
void test2() {
WebClient webClient = WebClient.create();
Mono<String> hello = webClient.get()
.uri("http://localhost:8080/sample?name={name}", "wonwoo")
.retrieve()
.bodyToMono(String.class);
StepVerifier.create(hello)
.expectNext("hello wonwoo!")
.verifyComplete();
}
@Test
void test1_3() {
WebClient webClient = WebClient.create();
Mono<String> hello = webClient.get()
.uri("http://localhost:8080/sample?name=wonwoo")
.retrieve()
.bodyToMono(String.class);
StepVerifier.create(hello)
.expectNext("hello wonwoo!")
.verifyComplete();
}
@Test
void test1_3() {
WebClient webClient = WebClient.create("http://localhost:8080");
Mono<String> hello = webClient.get()
.uri("/sample?name={name}", Map.of("name", "wonwoo"))
.retrieve()
.bodyToMono(String.class);
StepVerifier.create(hello)
.expectNext("hello wonwoo!")
.verifyComplete();
}
@Test
void test1_3() {
WebClient webClient = WebClient.create("http://localhost:8080");
Mono<String> hello = webClient.get()
.uri("/sample?name={name}", "wonwoo")
.retrieve()
.bodyToMono(String.class);
StepVerifier.create(hello)
.expectNext("hello wonwoo!")
.verifyComplete();
}
@Test
void test1_3() {
WebClient webClient = WebClient.create("http://localhost:8080");
Mono<String> hello = webClient.get()
.uri(it -> it.path("/sample")
.queryParam("name", "wonwoo")
.build()
).retrieve()
.bodyToMono(String.class);
StepVerifier.create(hello)
.expectNext("hello wonwoo!")
.verifyComplete();
}
| java 리스트간 비교, 값 체크 (0) | 2021.02.24 |
|---|---|
| Kafka (0) | 2021.02.24 |
| 비동기, 동기, 블로킹, 논블로킹 (0) | 2021.02.19 |
| JAVA11 (0) | 2019.10.04 |
| Oracle JDK 라이센스 전환 (0) | 2019.10.04 |